Benchmarking
✎Modified 2020-06-09 by Linus1994
Maintainer: Linus Lingg
Introduction
✎Modified 2020-06-11 by Linus1994
This section of the book focuses on the concept of behaviour benchmarking in Duckietown. There will be first a brief general introduction to introduce the general architecture of the Behaviour Benchmarking. The most important parts are explained as well as some general information is given. The presentation as well as the repository corresponding to the Behaviour Benchmarking are also available.
- Subsection 0.9.1 - Introduction
- Subsection 0.9.2 - General Architecture
- Subsection 0.9.3 - General Information
- Subsection 0.9.4 - Goal
- Subsection 0.9.5 - Future development
- Unit F-1 - Lane Following Benchmark Introduction
- Unit F-2 - Lane Following - Procedure
- Unit F-3 - Benchmarks for other Behaviours
General Architecture
✎Modified 2020-06-11 by Linus1994
Below you can see the general architecture that was set up for the Behaviour Benchmarking. The Nodes that are marked in green as well as the general architecture form are the same for no mather what behaviour that is benchmarked. The other nodes might vary slightly from behaviour to behaviour.
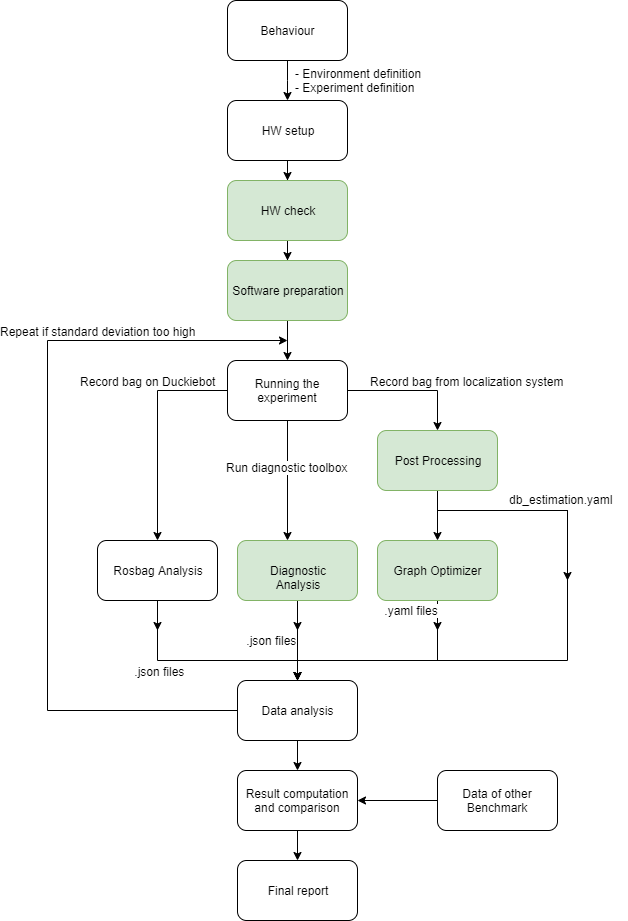
So first of all, the Behaviour defines the experiment definition as well as the environment definition. Based on that the hardware set up is explained and can be done. After this there will be a Hardware check which assures that everything is ready to compute results that can then be compared fairly with other Benchmarks of the same behaviour. Furthermore, the software set up will be explained and can be prepared. With all that done, it is all ready to run the actual experiments in which all the needed data is recorded. It is necessary to run at least two experiments to be able to check if the data received is reliable. Reliable means, that the there was no falsified measurement by the localization system for example, and that “lucky” runs can be excluded for sure. Therefore, the user is asked in the beginning to run at least two experiments, out of those measurements it will then later, based on the repetition criteria, be concluded if this data is reliable or if the user needs to run another experiment. Collecting all the needed data means that on one hand the diagnostic toolbox is running to record all kind of information about the overall CPU usage, memory usage etc as well as the CPU usage etc from all the different containers running and even of each node. On the other hand a bag is recorded directly on the Duckiebot which records all kind of necessary data published directly by the Duckiebot which are information about its estimations, the latency, update frequency of all the different topics etc. And last but not least, a bag is recorded that records everything from the localization system (same procedure as offline localization) which is taken as the Ground Truth . The localization system measures the position of the center of the April Tag placed on top of the localization standoff on the Duckiebot. So each time the position of the Duckiebot or the speed (for example time needed per tile etc) of the Duckiebot is mentioned it is always referred to the center of the AprilTag on top of the Duckiebot. This means that these results require that this April Tag has been mounted very precisely.
The recorded bags are then processed:
The one recorded on the Duckiebot is processed by the container analyze_rosbag which extracts the Information about latency, update frequency of the nodes as well as the needed information published by the Duckiebot and saves it into json files.
The one from the localization system is processed as explained in the classical offline localization system to extract the ground truth information about the whereabouts of the Duckiebot. The original post-processor just processes the apriltags and odometry from the bag and writes it in a processed bag. However, there exists a modified version which extract the relative pose estimation of the Duckiebot and write it directly in a .yaml file (More details are given below). The graph-optimizer then will extract the ground truth trajectories of all the Duckiebots that were in sight and store it in a yaml file.
The data collected by the diagnostic toolbox does not need any processing and only needs to be downloaded from this link.
The processed data is then analyzed in the following notebooks: 1. 95-Trajectory-statistics.ipynb: This extracts all the information measured by the localization system and calculates all the things related to the poses of the Duckiebots. 2. 97-compare_calc_mean_benchmarks.ipynb: In this notebook it is analyzed if the measurements are stable enough such they can be actually compared to other results. There the repetition criteria is checked and if the standard deviation is too high the user is told to run another experiment to collect more data. As soon as the standard deviation is low enough the mean of all the measurements is calculated and then stored into yaml file that then can be compared to other results. 3. 96-compare_2_benchmarks.ipynb: This notebook serves to do the actual comparison between two Benchmark results or to do an analysis of your Benchmark (if there is no other one to compare to). It analyzes the performance based on many different properties and scores the performance. In the very end a final report can be extracted which summarizes the entire Benchmark.
So let me specify a couple of things:
- The environment definition includes the map design, the number of Duckiebots needed to run this Benchmark, as well as the light condition.
- The experiment definition includes information about how to run the experiment in which all the data is collected. So where to place the Duckiebots involved, what to do, when the Benchmark is terminated etc. is defined there. Also, the metrics used to actually score the behaviour as well as the actual scoring definition are defined.
- Repetition criteria defines which data we look at to check if the results are kind of stable and therefor reliable. This is to sort out lucky runs for example. The reliability of the data is judged based on the Coefficient of Variation.
- The Software preparation: As this Behaviour Benchmarking is there to actually test the software , most of this is depending on which SW the user wants to test. However, it also includes the preparation of the localization system etc. Moreover, to test a specific component/packages of dt-core, there is a prepared repository to simply add your modified package and build/run it within a specific version of dt-core. This works for all kind of contributions to dt-core that can be used in lane_following and/or indefinite navigation. Also in this package, one can lighten the launch file a bit in case the contribution is not very stable.
- The Hardware Check: is a docker container based on a simple python script that runs the user through a couple of questions and verifies that all is done in a correct fashion and all is prepared to be later fairly compared to other results.
Please note that the analysis is also possible if not all the data is collected, for example if the user does not record a bag on the Duckiebot or if the Diagnostic Toolbox was not running. At the moment the data recorded from the localization system is necessary to get an actual scoring in the end, however this can easily be adapted.
General Information
✎Modified 2020-06-11 by Linus1994
All the packages created for the Behvaiour Benchmarkin can be found here. This repository includes the following new contributions:
-
Packages:
- 08-post-processing: Slightly modified version of the original post-processor which in addition to processing the bag also creates a yaml file including the relative lane pose estimations made by the Duckiebot.
- analyze_rosbag: Package to process the bag recorded directly on the Duckiebot and creates several .json file including the needed information about: updated frequency of the nodes that are recorded, latency up to and including the detector node, global constants that were set, number of segments detected at each time and the pose (offset and heading) estimation of the Duckiebot.
- hw_check: Package that guides the user through a checklist to make sure all the hardware is set up properly and to collect the information about the Duckiebot hardware used for the benchmarking.
- light_lf: This package is in the end the same as the dt-core, however it allows the user to easily add his contribution and to lighten the launch file for lane following and indefinite navigation.
-
Notebooks:
- 95-Trajectory-statistics: Analyzes the yaml file created by the graph-optimizer and the one created by the modified post-processor and extracts all kind of information related to the actual location of the Duckiebot.
- 97-compare_calc_mean_benchmarks: Analyzes the yaml file created by the notebook 95, the json file downloaded from the dashboard, as well as all the json files created by the analyze_rosbag package. It checks the reliability and computes a measurement summary that can be compared to others in the notebook 97
- 96-compare_2_benchmarks: Analyzed the yaml files created by the notebook 97 of two different benchmarks of the same behaviour, or just analysis the performance of one of them if only one is available. It will result in a nice overview of the general performance.
Please note, that for each notebook there exists an example notebook that shows the results computed when the notebook is run with actual data.
Goal
✎Modified 2020-06-11 by Linus1994
The goal of this Behaviour Benchmarking is that for each behaviour and each major version (Ex: Master19, Daffy, Ente etc) there is a huge data set out of which the mean of all the measurements is calculated to build a stable and very reliable reference Benchmark. The developer can then compare its contribution to the results achieved by the global Duckietown performance.
At the moment the user is asked to upload its recorded bags to this link. However, this link should be changed as soon as possible as the storage is limited. The data storage should be automated anyways.
Future development
✎Modified 2020-06-11 by Linus1994
To design a Behaviour Benchmark in the future, all the needed packages and notebooks can be found in this repository, simply (fork and) clone it and then add your contribution. The readme file found in the repository corresponds to the set up and preparation of the lane following benchmark. Just copy it and adapt the sections that need to be changed. The most important sections that need to be adapted are the actual environment and experiment set up and the topics one has to subscribe to for the bag recorded on the Duckiebot.
- If needed adapt the the modified post-processor package by adding your code here, such that other things are extracted out of the bag then just the pose estimation of the Duckiebot for example.
- The Hardware check should remain the same.
- Adapt analyze_rosbag such that the additional information needed for your specific benchmark is extracted out of the bag recorded on the Duckiebot, by editing this file.
- Adapt the notebooks such that they analyze the things needed for your specific benchmark, however, it is strongly recommended to keep the same structure of first analyzing the measurements of the localization system, then check the consistency of the data and summarize it in one yaml file which then can be compared to other Benchmarks.